
LUG Erding
Bislang hatten wir uns immer gezielt einige Bereiche angesehen, wie Linux-Grundlagen, TCP/IP, Fehlersuche in Netzwerken, DNS und HTTP. Doch wie alles zusammenspielt haben wir so nicht direkt betrachet. Das soll hier exemplarisch am Zugriff auf eine Webseite gezeigt werden.
Dabei ist hoffentlich alles enthalten: Zerlegen der URL, finden des Servers, holen der Seite und anschließender Darstellung.
Der verwendete Testaufbau sieht so aus:
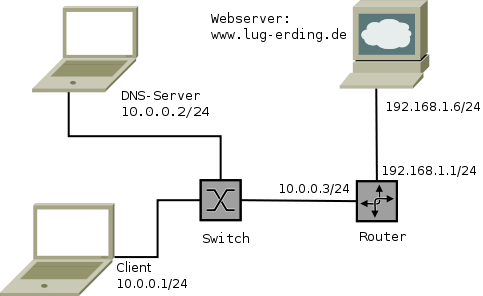
Der erste Schritt besteht in der Analyse der URL, so wird diese in die drei wichtigen Bestandteile zerlegt:
Beim Protokoll wird gewöhnlich HTTP verwendet, das Hypertext Transfer Protocol. Wird kein Port angegeben, so ist es der www-Port oder auch der http-Port, das ist ein alias, aus /etc/services:
www 80/tcp http # WorldWideWeb HTTP www 80/udp # HyperText Transfer Protocol
Definiert sind die Services in der Regel immer für beide Protokolle, also TCP und UDP. Nur wird wohl keiner jemals UDP für HTTP verwenden.
Neben HTTP wird oft noch HTTP over SSL/TLS verwendet, das wird durch https angegeben. Dabei wird zwischen dem Transportprotokoll TCP und dem HTTP noch eine Verschlüsselungsschicht eingebaut. Dann gibt es oft noch FTP, dann wird ganz normal Port 21 verwendet. Aber auch der Zugriff auf lokale Dateien ist mit file möglich.
Nach dem Protokoll folgt ein Doppelpunkt und zwei Slashes ://, bis zum nächsten Slash folgt dann der Servername, gefolgt von dem Pfad auf dem Zielsystem. Also bei
http://www.lug-erding.de/index.html
ist HTTP das Protokoll, www.lug-erding.de ist der Servername und /index.html ist der Pfad zu den Daten auf dem Zielsystem. Gewöhnlich kann index.html weggelassen werden, dann besteht der Pfad nur aus einem "/". Der Webserver liefert dann in aller Regel die Datei index.html aus, oder eine Lokalisierung wie z.B. index.html.de, falls der Browser die deutsche Sprache bevorzugt.
Wer sich schon einmal gewundert hat, warum der Browser beim Zugriff auf lokale Dateien 3 Slashes in die URL einbaut, hat nun die Antwort: Der Servername ist leer. Anderenfalls würde er den ersten Pfadteil als Servernamen interpretieren. Das ergibt bei file natürlich keinen Sinn.Die URL für den lokalen Dateizugriff könnte dann also so aussehen:
file:///home/geschke/WEB/indx.html
Auch die Protokollnamen, TCP oder UDP, also das nächst höhere Protokoll nach IP, kann in die entsprechenden Zahlenwerte per /etc/protocols aufgelöst werden:
tcp 6 TCP # transmission control protocol udp 17 UDP # user datagram protocol
TCP ist also das IP-Protokoll mit der Nummer 6, UDP hat die Nummer 17. Es ist auch später entstanden und deutlich einfacher als TCP.
Ein Browser kann natürlich versuchen die Seite direkt vom Server zu laden, es ist aber auch möglich, die Seite über einen (caching) Webproxy zu holen. Das kann den Vorteil haben, dass Daten dort gecachet werden können oder auch einfach nur verschiedene Wege zu den Servern hier zentral gepflegt werden können. Auch besteht hier die Möglichkeit zentral den Zugriff zu reglementieren.
Wenn der Browser also für den Gebrauch eines Proxys konfiguriert ist, so muss er auch wissen, welchen Proxy er wann verwenden soll.
Da gibt es mehrere Möglichkeiten:
Bei der PAC-Datei und der wpad.dat wird ein kleines JavaScript-Programm geladen, über dieses können verschiedene Proxys je nach Art der URL verwendet werden.
Bei der manuellen Konfiguration kann nur ein Proxy angegeben werden, es besteht jedoch die Möglichkeit, Ausnahmen zu definieren. Diese werden dann direkt vom Server bezogen und nicht via Proxy.
Die über das Netzwerk automatisch erkannten Proxy-Einstellungen können auf vielfache Weise ermittelt werden. Das kann durch suchen nach einem Webserver in der eigenen Domain oder via DHCP oder via DNS.
Das hatten wir schon beim Squid-Vortrag und man kann es auch hier gut nachlesen:
Hier wird aber auch mitunter der nächste Schritt schon relevant: Die Namensauflösung. Gerade wenn Namen und Ausnahmen für IP-Adressen verwendet werden oder die PAC-Datei auf Basis von IP-Adressen den zuständigen Proxy bestimmen will, so wird auch eine Namensauflösung benötigt. Hier wird DNS notwendig, das ist auch ein Vorteil vom Proxy, da kann man leichter die Namensauflösung konfigurieren.
Sollten also beim Surfen immer eine Verzögerung von 5-10 Sekunden bei Erstzugriffen bemerkt werden, dann könnte es an der fehlerhaften Namensauflösung liegen. Das ist der typische Zeitraum, wann der Resolver aufgibt und der Browser einfach alles über den definierten Default-Proxy abwickelt.
naWird die Namensauflösung nicht über den Proxy geregelt oder der Proxy wird mit Namen statt IP-Adresse angegeben, so muss der Client, also der eigene PC, den Namen auflösen.
Nun wie erfolgt das?
Es gibt mehrere Verfahren, wie ein System vom Namen zur IP-Adresse kommen kann. Unter Linux wird das über den hosts-Eintrag in der Datei
/etc/nsswitch.conf
geregelt. Bei mir steht da zum Beispiel:
hosts: files dns
In diesem Fall wird der Name zuerst in der lokalen Datei
/etc/hosts
gesucht. Steht hier der Name mit einer IP-Adresse, so wird die Suche abgebrochen und die Adresse verwendet. Damit kann man zum Beispiel die Adressen, die sonst vom DNS-Server geholt würden, überladen. Für Testzwecke kann das manchmal hilfreich sein, manche verwenden es auch um DoubleClick oder Google-Analytics auf 127.0.0.1 umzubiegen. Damit gibt es keine Werbung beziehungsweise Verfolgung der Webaufrufe.
Kann der Name nicht aufgelöst werden, so erfolgt dann die Abfrage von DNS-Servern. Hierfür ist die Datei
/etc/resolv.conf
relevant. In ihr können bis zu drei Nameserver stehen, es kann auch eine Suchdomain angegeben werden: Wird der direkte Name nicht gefunden, so werden nach und nach die angegebenen Domainnamen angefügt und die Suche erneut gestartet bis eine IP-Adresse gefunden wird. Anderenfalls wird ein Fehler zurückgeliefert, der Browser hängt eine zeitlang und liefert dann eine entsprechende Fehlermeldung.
Ferner könnten in nsswitch.conf auch noch nis/nisplus oder ldap stehen. Das dürfte heute aber kaum noch jemand für die Namensauflösung verwenden. Hat man jedoch den Avahi-Daemon installiert, das ist ein sogenanntes Zeroconf-Programm wie Rendezvous oder Bonjour, gibt es noch ein Verfahren mehr. Mit Avahi kann ein Netzwerk ohne eigenes zutun, lediglich durch das Verkabeln, aufgebaut werden. Dem einen oder anderen sind diese Adressen bestimmt schon begegnet, sie liegen im Bereich 169.254.x.y. Warum man für so etwas ein ganzes Class-B Netz verschwendet, ist eine andere, wenn auch gute Frage. Oft wird dieser Daemon durch die Distribution automatisch mit installiert. Dann gibt es noch die Option mdns, der Eintrag in /etc/nsswitch.conf kann dann so aussehen:
hosts: files mdns4_minimal [NOTFOUND=return] dns mdns4
Diese mdns-Einträge suchen via Multicast nach der IP-Adresse, das heißt sie rufen in das Netzwerk hinein ob jemand die IP-Adresse zu dem Namen hat oder weiß. Meldet sich hier ein System mit Nein, so bricht die Suche ab!
Man sollte diesen ganzen Avahi-Krempel einfach wegwerfen, er stört mehr als das er hilft. Wer von Netzwerken keine Ahnung hat, der soll einfach die Finger davon lassen und sich nicht auf die Magie des Betriebssystems verlassen. Aber das ist nur meine persönliche Meinung...
Aber dummerweise installieren viele Distributionen das Teil automagisch mit.
Idealerweise sollte man also nur
hosts: files dns
in der Datei /etc/nsswitch.conf stehen haben. Ferner sollte in der /etc/hosts immer der Name localhost enthalten sein:
127.0.0.1 localhost
Localhost wird von vielen lokalen Diensten verwendet, der Name sollte also zum einen immer auflösbar sein und zum anderen auf die Loopback-Adresse verweisen. Sonst kann man schon seltsame Effekte erleben...
Da wir nun wissen, wie die Namensauflösung erfolgt, gehen wir nun davon aus, dass ein DNS-Server involviert ist und wir nicht über /etc/hosts-Auflösungen surfen. Jetzt kommen wir in den Netzwerkbereich: Wie wird der DNS-Server im Internet gefunden?
Zur kurzen Erinnerung an TCP/IP: Das Protokoll besteht aus mehreren, unabhängigen Schichten, jede Schicht hat sein eigenes Protokoll und seine eigene Aufgabe. Oft wird dafür auch das OSI-Modell mit seinen 7 Schichten herangezogen. TCP/IP hält sich aber nur für die ersten Schichten daran.
Relevant sind hier die ersten 4 Schichten:
Die erste Schicht betrifft nur die Art der Verkabelung oder die Art des Funks. Relevant wird es mit der Schicht 2, das ist in aller Regel Ethernet. Früher war hier oft auch noch Token Ring verbreitet, das kommt aber wohl nur noch selten zum Einsatz. Aber das zeigt den klaren Vorteil des Schichtenmodells. Die höheren Schichten brauchen nicht zu wissen ob Ethernet, WLAN oder gar Token Ring zum Einsatz kommen. Ebenso brauchen TCP/UDP nicht zu wissen, ob darunter ein IPv4 oder ein IPv6 verwendet werden. Das macht es so leicht, hier andere Protokolle zu verwenden oder diese auszutauschen.
Für das Weitere gehen wir einfach von Ethernet aus.
IP ist das Protokoll, dass die Internetsysteme miteinander verbindet, das ist die Adressierung der Systeme an Hand der IP-Adressen.
Für das lokale Netzwerk, also bis zum direkt angeschlossenen System oder dem Router/Gateway ist aber Ethernet zuständig.
Wie wird denn nun der DNS-Server gefunden?
Dazu muss man wissen, wie er erreicht werden kann. Ein Blick in die Routing-Tabelle offenbart dann, ob der DNS-Server lokal angeschlossen ist, also im gleichen Subnetz steht oder ob er über einen Router erreicht werden muss.
Die logische Adressierung erfolgt über die IP-Adresse. Der Versand zum nächsten angeschlossenen System, also dem Server oder Router, erfolgt aber über Ethernet. Wir müssen also erst einmal die Ethernetadresse des Systems finden, alles was wir haben ist aber eine IP-Adresse.
Das erfolgt mit dem Address-Resolution-Protocol. Dabei sendet das suchende System, also der eigene PC, ein spezielles Ethernetpaket an alle angeschlossenen Systeme und fragt nach der Hardware-Adresse zu der gewünschten IP-Adresse, also entweder dem DNS-Server wenn er direkt im Subnetz steht oder die des zuständigen Routers.
Die Hardware-Ethernet-Adresse besteht bei Ethernet aus 6 Bytes und die sind für alle Ethernetkarten eindeutig. Sie werden auch MAC-Adresse, Media Access Control Adresse, genannt. Die ersten 3 Bytes identifizieren dabei den Hersteller der Ethernetkarte, die restlichen 3 Bytes eine einmalige Adresse bei just diesem Hersteller.
Diese Adressen werden in der Regel als Hexadezimalzahlen, getrennt durch Doppelpunkte, dargestellt, z.B.:
00:1a:70:63:16:f5
Die ersten 3 Bytes liefern dann über
http://standards.ieee.org/regauth/oui/oui.txt
den Hersteller der Karte:
00-1A-70 (hex) Cisco-Linksys, LLC
Es gibt auch spezielle Adressen, wie zum Beispiel die Broadcast-Adresse der Schicht 2. Bei dieser sind alle Bits gesetzt:
ff:ff:ff:ff:ff:ff
Da die Zieladresse zuerst im Ethernet-Header steht, können alle Ethernetkarten leicht erkennen, ob das Paket für sie bestimmt ist, sie kennen ja die eigene MAC-Adresse. Bei Broadcast-Adressen wissen die Karten dann durch die spezielle Adresse auch gleich, dass sie dieses Paket entgegen nehmen sollen.
Derartige Pakete nimmt also jede direkt angeschlossene Ethernetkarte an und leitet es an das Betriebssystem weiter.
Bei einem ARP-Request steht dann in den Nutzdaten, dass das eigene System die MAC-Adresse zu der angegebenen IP-Adresse sucht. Da alle Systeme diese sehen, sollte das System antworten, dass die IP-Adresse besitzt. Das ist der ARP-Response.
Mit anderen Worten:
Wer einen Blick auf das Bild des Vortrages wirft, der sieht nun, dass wir die MAC-Adresse vom DNS-Server mit der IP-Adresse 10.0.0.2 suchen. Das ist in der lug.pcap-Datei der erste Eintrag:
00:13:77:5b:25:ad > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: arp who-has 10.0.0.2 tell 10.0.0.1
Das ist der Broadcast, zu erkennen an dem Ziel ff:ff:ff:ff:ff:ff. Die erste Adresse ist die eigene MAC-Adresse, an die werden die Antworten direkt übertragen. Diese Nachricht wird an alle Ethernetkarten gesendet, die im gleichen Segment stecken. Die Karten nehmen dieses Paket dann entgegen und reichen es an den Kernel weiter. Dieser antwortet dann, sofern er die IP-Adresse besitzt:
00:1e:68:ef:be:63 > 00:13:77:5b:25:ad, ethertype ARP (0x0806), length 60: arp reply 10.0.0.2 is-at 00:1e:68:ef:be:63
Hier sieht man noch mehr. Im ARP-Request steht neben der gesuchten Adresse auch die eigene. Damit kann das System, das gesucht wird, sich schon einmal die IP-Adresse und MAC-Adresse des Anfragenden merken (ARP-Cache), denn es gibt wohl eine hohe Wahrscheinlichkeit, dass da gleich noch mehr Netzwerkpakete kommen werden.
Die Antwort wird auch direkt an die MAC-Adresse des Fragenden gesendet, der Absender besitzt die MAC-Adresse und auch die IP-Adresse des gesuchten Systems.
BTW: Bei DHCP wird in der Regel auch erst ein ARP-Request für die frisch vergebene IP-Adresse vom System selber versendet. Damit wird getestet, ob die nicht schon im Netzwerk existiert, also jemand diese vielleicht von Hand konfiguriert hatte.
Das war ein kurzer Ausflug in die Data-Link-Schicht, wer es genauer wissen will, kann hier noch mehr Infos finden:
Nachdem wir nun wissen, wie der DNS-Server oder der Router zum Ziel gefunden werden, können wir das IP-Paket auf die Reise schicken. Im Fall von DNS ist das in der Regel ein UDP-Paket an Port 53 des Servers. Hier sehen wir dann allerdings zwei, einmal eine Anfrage für die IPv4-Adresse und einmal die für die IPv6-Adresse (auch die kann via IPv4 aufgelöst werden, sofern sie denn existiert):
IP (tos 0x0, ttl 64, id 16351, offset 0, flags [DF], proto UDP (17), length 63) 10.0.0.1.40105 > 10.0.0.2.53: 30718+ A? www.lug-erding.de. (35) IP (tos 0x0, ttl 64, id 16352, offset 0, flags [DF], proto UDP (17), length 63) 10.0.0.1.40105 > 10.0.0.2.53: 9550+ AAAA? www.lug-erding.de. (35)
Die MAC-Adressen (und Zeiten) habe ich hier weggelassen. Man sieht dafür hier diverse Werte aus dem IP-Header. So wird hier kein TypeOfService verwendet, das Feld wird heute auch eher als QoS, Quality Of Service oder DiffServ verwendet.
Interessant ist noch die TTL: Diese gibt an, wie lange das IP-Paket weitergeleitet werden darf. Jeder Router verringert diesen Wert um 1, landet ein System bei 0, so wird das Paket verworfen und an den Absender wird ein ICMP Time Exceeded gesendet um ihn darüber zu informieren.
Das Porgramm traceroute verwendet zum Beispiel diese Option um den Weg der Pakete zu bestimmen. Dabei wird sukzessive der Wert von 1 hochgezählt. Bei einem Wert von 1 antwortet der erste Router, bei 2 der zweite, etc. bis man am Zielsystem angekommen ist. Da die Router die ICMPs mit der eigenen IP-Adresse versenden, kann so (der momentane Weg) bestimmt werden.
Die ID ist wohl selbsterklärend, sie spielt in Verbindung mit offset eine Rolle. Müssen die IP-Pakete unterwegs zerlegt werden da nur kleinere Bestandteile weitergeleitet werden können, DSL hat zum Beispiel eine MTU von 1492, Ethernet jedoch von 1500 Bytes, so kann über die ID und dem offset bestimmt werden, wozu die Daten gehören.
Das DF-Flag verbietet deine Zerlegung in kleinere Pakte: Don't Fragment.
Das heißt wenn eine Fragmentierung notwendig ist, darf das auf Grund dieses Flags nicht erfolgen. Stattdessen wird das Paket verworfen und eine ICMP-Meldung wird an den Absender geschickt. Diese besagt, dass das Paket verworfen wurde, da es zu groß war. Gleichzeitig wird noch mitgesendet, was die maximale Größe ist, die möglich wäre um es weiterzuleiten.
Wenn man also per Ethernet an seinen DSL-Router Pakete mit 1500 Bytes Größe sendet, so zerlegt der Router dieses Paket in zwei: Einmal 1492 Bytes und einmal 28 Byte, 20 Byte für einen neuen IP-Header plus die fehlenden 8 Bytes. Letzteres wird noch durch Füllbytes auf eine Mindestgröße aufgeblasen. Der Empfänger muss diese Pakete dann wieder zusammenbasteln.
Bei gesetztem DF-Bit, wird das Paket verworfen, der ICMP wird gesendet und das sendende System erkennt nun: Mehr als 1492 Bytes geht nicht. Folglich werden dann alle Pakete mit einer maximalen Größe von 1492 Bytes versendet, es gibt keine Fragmentierung und auch nicht zwei statt einem Paket. Das erhöht den Durchsatz deutlich.
Die Werte danach besagen, dass die nächste Schicht UDP enthält, das ist laut
/etc/protocols
udp 17 UDP # user datagram protocol
Danach folgen die IP-Adressen und UDP-Ports. Der Client-Port ist in aller Regel beliebig, der Zielport mit 53 (domain aus /etc/servcies) fest, also:
Ursprung : 10.0.0.1 Quellport: 40105 Ziel : 10.0.0.2 Zielport : 53
Anschließend kommt die Payload, also die eigentlichen Daten die per UDP übermittelt werden. Das ist die Frage nach dem A- und AAAA-Record, also der IPv4 bzw. IPv6 Adresse von www.lug-erding.de.
Die IPv6-Adresse existiert in diesem Umfled nicht, es gibt aber eine IPv4-Adresse. Ich habe hier die Ausgabe wieder etwas gekürzt:
IP 10.0.0.2.53 > 10.0.0.1.40105: 30718* 1/1/1 A 192.168.1.6 (85)
Und schon sind wir am Ziel: Wir haben die IP-Adresse des Webservers gefunden. War doch gaaaanz einfach...
Eine Frage dürfte noch aufgetreten sein: Wie bekommt der Nameserver diese Adresse, wenn er nicht für die Domain zuständig ist? Die Antwort ist einfach, der Nameserver muss eine rekursive Namensauflösung zulassen und dieser hangelt sich dann beginnend beim Root-Nameserver durch, bis er beim zuständigen Nameserver für die Domain angekommen ist. Dort erhält er die korrekte Antwort und leitet diese dann weiter.
Details dazu kann man hier finden:
Oh, schon wieder eine Eigenwerbung...
Da wir jetzt die IP-Adresse des Servers haben, geht es fast analog zur Suche des Nameservers weiter. Zuerst wird die Routingtabelle analysiert um herauszufinden, was der nächste Hop ist, also an welche MAC-Adresse das IP-Paket gesendet werden soll.
Die Routingtabelle wird bei Unix mit netstat -r ausgeben, ein -n hilft dabei, die Namensauflösung zu unterdrücken. Bei Linux kann man auch einfach das route-Kommando verwenden, es liefert die gleiche Ausgabe.
$ netstat -rn Kernel IP routing table Destination Gateway Genmask Flags MSS Window irtt Iface 10.0.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 0.0.0.0 10.0.0.3 0.0.0.0 UG 0 0 0 eth0
Es gibt hier nur zwei Einträge. Der erste betrifft das eigene Subnetz, d.h. alles was im Bereich von 10.0.0.0 bis 10.0.0.255 liegt (der Bereich wird durch die Netzmaske festgelegt), wird direkt über eth0 zugestellt. D.h. es wird ein ARP-Request direkt für das Zielsystem gesendet.
Der zweite Eintrag betrifft die Default-Route, das heißt für alle Adressen für die es keinen Eintrag gibt, ist dieser zuständig. In unserem Fall ist der Zielserver 192.168.1.6, dieser muss also über die Default-Route erreicht werden.
Bei Gateway steht nun der Router, der den Weg zum Ziel (hoffentlich) weiß. Folglich wird ein ARP-Request gesendet um die MAC-Adresse zu der IP-Adresse 10.0.0.3 zu finden:
00:13:77:5b:25:ad > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: arp who-has 10.0.0.3 tell 10.0.0.1 00:0d:b9:1f:13:7e > 00:13:77:5b:25:ad, ethertype ARP (0x0806), length 60: arp reply 10.0.0.3 is-at 00:0d:b9:1f:13:7e
Der Rest läuft nun analog, nur werden die Pakete diesmal zum Router gesendet. Der nimmt diese entgegen und sucht das nächste Ziel. Dann werden die MAC-Adressen ausgetauscht, die TTL wird um eins reduziert und das Paket geht zum nächsten Router (aka Hop).
Da HTTP in der Regel via TCP erfolgt, wird ein TCP-Paket gesendet:
00:13:77:5b:25:ad > 00:0d:b9:1f:13:7e, ethertype IPv4 (0x0800), length 74: 10.0.0.1.47401 > 192.168.1.6.80: S 1287558560:1287558560(0) win 5840 <mss 1460,sackOK,timestamp 1064977 0,nop,wscale 7>
Hier sieht man die MAC-Adressen, analog zur DNS-Anfrage. Die Ziel-MAC-Adresse ist die vom Router. Im IP-Header (oben nicht angezeigt) steht jetzt statt UDP diesmal TCP. Das kann man auch an dem S erkennen. Das ist ein SYN-Paket, der Client möchte eine Verbindung zum Server öffnen und bitte um SYNchronisation. Es folgen eine Sequence-Nummer, die Windowgröße, das heißt soviele Bytes darf einem der Server senden bevor der Empfang bestätigt werden muss. Ferner gibt es noch ein paar weitere Optionen. Hier besagen sie, dass SACK, Selektives Bestätigen von Paketen erlaubt ist, es werden Zeitstempel zur Bestimmung der Laufzeiten verwendet und mit wscale können größere Windows angegeben werden, als ursprünglich vom Protokoll erlaubt waren.
MSS gibt die Maximum Segement Size an, also die maximale Größe für die Payload also die Nutzdaten im TCP. Der IP-Header ist gewöhnlich 20 Bytes groß, der TCP-Header ebenfalls. Das macht bei Ethernet einen Wert von 1500-20-20=1460. Das ist die maximale Payload, die ein System senden darf, sie kann sich noch einmal etwas verringern, wenn die Gegenstelle Optionen von TCP verwendet, dann wird der TCP-Header größer. Das ist dann aber ein Problem der Gegenstelle, die muss das berücksichtigen und die Payload entsprechend verkleinern.
Auf das SYN folgt dann diese Antwort:
00:0d:b9:1f:13:7e > 00:13:77:5b:25:ad, ethertype IPv4 (0x0800), length 74: 192.168.1.6.80 > 10.0.0.1.47401: S 1133845053:1133845053(0) ack 1287558561 win 5792 <mss 1460,sackOK,timestamp 388120 1064977,nop,wscale 2>
Das sieht analog zu obigem aus, interessant ist zu sehen, dass hier als Absender wieder die MAC-Adresse des Routers auftaucht obwohl die Antwort vom Webserver stammt. Der Server sendet seinerseit auch ein SYN, er will die Verbindung in Rückrichtung ebenfalls öffnen. Gleichzeitig sendet er auch ein ACK mit, damit ACKnowledged er den Verbindungswunsch.
Die ACK-Nummer ist dabei die Sequenznummer vom Client plus eins. Danach kommen noch die TCP-Optionen vom Server. Dieser verwendet ebenfalls Zeitstempel. Hier sieht man nun zusätzlich den Zeitstempel des Clients, das heißt in der Antwort steckt die Uhrzeit, die der Client versendet hat. Darüber kann nun leicht die Laufzeit bestimmt werden, man muss sich also keine Gedanken darüber machen ob die Zeiten synchron sind oder nicht. Es zählt immer nur die eigene Uhrzeit! Um genau zu sein, braucht die Uhrzeit auch nicht genau sein, es zählt nur die Zeit, bis man diesen Wert wiedersieht.
Was hat es nun mit den Sequenz- und Acknummern auf sich? Ganz einfach, darüber wird geklärt, wo die Daten einzuordnen sind. Im Internet ist es zum Beispiel nicht gewährleistet, dass die Pakete in der richtigen Reihen- folge oder nur einmal aufschlagen.
Der Trick ist nun, dass die Sequenznummer anzeigt, wo im Datenpaket die folgenden Bytes liegen, es ist der Startwert. Die Acknowledge-Nummer gibt wiederum an, welche Daten von der Gegenstelle man erhalten hat. Dabei zeigt die ACK-Nummer auf das erste Byte, das noch fehlt, also Die Sequenznummer aus dem SYN-Paket plus die bereits empfangenen Daten plus eins.
Das Programm tcpdump ist so freundlich, und zieht diese Startzahlen bei der Darstellung gleich ab, dann braucht man selber nicht mehr rechnen und weiß, wieviele Bytes angekommen sind.
Das dritte Paket sieht dann, etwas gekürzt, so aus:
IP 10.0.0.1.47401 > 192.168.1.6.80: . ack 1 win 46 <nop,nop,timestamp 1064978 388120>
Hier bedeutet ack 1, dass noch gar keine Bytes empfangen wurden. Das ist klar, in den SYN-Paketen sind auch keine Daten enthalten, das sind nur IP-Pakete mit TCP-Header.
Ab dieser Stelle ist der sogenannte TCP-Handshake abgeschlossen, diese Verbindung ist nun aktiv. Um es zu wiederholen:
Jetzt ist die TCP-Verbindung aufgebaut, es sind aber noch keine Nutzdaten übertragen worden. Das folgt dann im 4. Paket, hier fließen dann tatsächlich Daten:
IP 10.0.0.1.47401 > 192.168.1.6.80: P 1:176(175) ack 1 win 46 <nop,nop,timestamp 1064978 388120>
Hier sieht man, dass 175 Bytes übermittelt wurden. Man sieht aber auch noch mehr, ein Push-Flag. Das ist die Aufforderung an die Gegenstelle, dass die Daten nicht mehr gesammelt werden sollen. Der Kernel reicht diese daraufhin an die Anwendung weiter.
Man kann es sich jetzt denken: In dem Paket ist der vollständige HTTP-Request enthalten. Mehr Daten will der Client jetzt noch nicht senden, nun ist erst einmal der Server an der Reihe.
Wird das Paket genauer angeschaut (Option -X bei tcpdump), so sieht man:
21:31:00.912680 IP 10.0.0.1.47401 > 192.168.1.6.80: P 1:176(175) ack 1 win 46 <nop,nop,timestamp 1064978 388120>
0x0000: 4500 00e3 d5b3 4000 4006 98b2 0a00 0001 E.....@.@.......
0x0010: c0a8 0106 b929 0050 4cbe 95a1 4395 1a3e .....).PL...C..>
0x0020: 8018 002e cc84 0000 0101 080a 0010 4012 ..............@.
0x0030: 0005 ec18 4745 5420 2f20 4854 5450 2f31 ....GET./.HTTP/1
0x0040: 2e31 0d0a 436f 6e6e 6563 7469 6f6e 3a20 .1..Connection:.
0x0050: 636c 6f73 650d 0a41 6363 6570 742d 4368 close..Accept-Ch
0x0060: 6172 7365 743a 2075 7466 2d38 2c2a 3b71 arset:.utf-8,*;q
0x0070: 3d30 2e38 0d0a 4163 6365 7074 2d45 6e63 =0.8..Accept-Enc
0x0080: 6f64 696e 673a 2067 7a69 700d 0a48 6f73 oding:.gzip..Hos
0x0090: 743a 2077 7777 2e6c 7567 2d65 7264 696e t:.www.lug-erdin
0x00a0: 672e 6465 0d0a 5265 6665 7265 723a 2068 g.de..Referer:.h
0x00b0: 7474 703a 2f2f 7777 772e 6c75 672d 6572 ttp://www.lug-er
0x00c0: 6469 6e67 2e64 652f 0d0a 5573 6572 2d41 ding.de/..User-A
0x00d0: 6765 6e74 3a20 4469 6c6c 6f2f 322e 320d gent:.Dillo/2.2.
0x00e0: 0a0d 0a ...
Links ist die Byte-Nummer des Zeilenanfangs, dann kommen die Rohdaten des IP-Paketes in Hexadezimaldarstellung und rechts wird die ASCII-Darstellung der Zeichen ausgegeben. Punkte sind dabei nicht darstellbare Zeichen oder auch Leerzeichen. Wird der IP-Header und TCP-Header abgezogen, dann bekommt man:
GET / HTTP/1.1 Connection: close Accept-Charset: utf-8,*;q=0.8 Accept-Encoding: gzip Host: www.lug-erding.de Referer: http://www.lug-erding.de/ User-Agent: Dillo/2.2
Das ist also der vollständige HTTP-Request. Wer Details dazu braucht, der wird hier mehr finden:
Was in der obigen Ausgabe auch gut gesehen werden kannr, das ist die Sequenz 0d0a0d0a ganz am Ende. Ein Blick in die ASCII-Tabelle (Tipp: man ascii liefert:
012 10 0A LF '\n' (new line) 015 13 0D CR '\r' (carriage ret)
Der erste Wert ist oktal, also Basis 8, dann dezimal gefolgt von hexadezimal. Danach folgt das eigentliche Zeichen: Zeilenvorlauf und Zeilenrücklauf, so wie es bei der guten alten Schreibmaschine war. Das ganze zweimal, einmal für den Zeilenabschluss und einmal für eine Leerzeile.
Es wird hier also nicht, wie in Unix üblich, nur ein new line aka line feed für den Zeilenabschluss verwendet.
Nachdem der Client nun den Request abgesendet hat (Push-Flag um dies dem anderen System anzudeuten), ist nun der Server an der Reihe. Zuerst wird der HTTP-Request bestätigt:
IP 192.168.1.6.80 > 10.0.0.1.47401: . ack 176 win 1716 <nop,nop,timestamp 388120 1064978>
Das heißt der Kernel reicht nun die Daten (den HTTP-Request) an den Webserver weiter. Dieser analysiert ihn und antwortet darauf (ich habe hier einmal die TCP-Optionen weggelassen, die verwirren nur und enthalten keine hier relevanten Informationen):
IP 192.168.1.6.80 > 10.0.0.1.47401: . 1:1449(1448) ack 176 win 1716 IP 10.0.0.1.47401 > 192.168.1.6.80: . ack 1449 win 69 IP 192.168.1.6.80 > 10.0.0.1.47401: . 1449:2897(1448) ack 176 win 1716 IP 10.0.0.1.47401 > 192.168.1.6.80: . ack 2897 win 91 IP 192.168.1.6.80 > 10.0.0.1.47401: . 2897:4345(1448) ack 176 win 1716 IP 10.0.0.1.47401 > 192.168.1.6.80: . ack 4345 win 114 IP 192.168.1.6.80 > 10.0.0.1.47401: FP 4345:4604(259) ack 176 win 1716 IP 10.0.0.1.47402 > 192.168.1.6.80: S 1285270109:1285270109(0) win 5840 IP 192.168.1.6.80 > 10.0.0.1.47402: S 1135847585:1135847585(0) ack 1285270110 win 5792 IP 10.0.0.1.47402 > 192.168.1.6.80: . ack 1 win 46 IP 10.0.0.1.47403 > 192.168.1.6.80: S 1290686861:1290686861(0) win 5840 IP 192.168.1.6.80 > 10.0.0.1.47403: S 1138145597:1138145597(0) ack 1290686862 win 5792 IP 10.0.0.1.47403 > 192.168.1.6.80: . ack 1 win 46 IP 10.0.0.1.47401 > 192.168.1.6.80: F 176:176(0) ack 4605 win 137 IP 10.0.0.1.47402 > 192.168.1.6.80: P 1:188(187) ack 1 win 46 ....
Hier kann noch etwas beobachtet werden: Erst werden die Daten gesendet und auch bestätigt. Dann schließt der Webserver die Verbindung mit einem FP, aber der Client macht gleich darauf noch zwei Verbindungen auf, einmal mit dem Source-Port 47402 und einmal mit 47403.
Warum macht er das? Ganz einfach: Nachdem die Datei index.html übertragen worden war, hat der Client diese analysiert und gesehen, dass da noch mehr Elemente nachgeladen werden müssen. Dafür öffnet er dann mehrere Verbindungen um die Daten parallel zu laden. Diese könnten auch auf anderen Servern vorhanden sein, dann wäre es vermutlich deutlich schneller.
Mit tcpdump kann man aber auch gezielt nur eine Verbindung heraussuchen, zum Beispiel durch Angabe des Source-Ports:
tcpdump -n -r lug.pcap port 47401
Das liefert, etwas gestutzt:
IP 10.0.0.1.47401 > 192.168.1.6.80: S 1287558560:1287558560(0) win 5840 IP 192.168.1.6.80 > 10.0.0.1.47401: S 1133845053:1133845053(0) ack 1287558561 win 5792 IP 10.0.0.1.47401 > 192.168.1.6.80: . ack 1 win 46 IP 10.0.0.1.47401 > 192.168.1.6.80: P 1:176(175) ack 1 win 46 IP 192.168.1.6.80 > 10.0.0.1.47401: . ack 176 win 1716 IP 192.168.1.6.80 > 10.0.0.1.47401: . 1:1449(1448) ack 176 win 1716 IP 10.0.0.1.47401 > 192.168.1.6.80: . ack 1449 win 69 IP 192.168.1.6.80 > 10.0.0.1.47401: . 1449:2897(1448) ack 176 win 1716 IP 10.0.0.1.47401 > 192.168.1.6.80: . ack 2897 win 91 IP 192.168.1.6.80 > 10.0.0.1.47401: . 2897:4345(1448) ack 176 win 1716 IP 10.0.0.1.47401 > 192.168.1.6.80: . ack 4345 win 114 IP 192.168.1.6.80 > 10.0.0.1.47401: FP 4345:4604(259) ack 176 win 1716 IP 10.0.0.1.47401 > 192.168.1.6.80: F 176:176(0) ack 4605 win 137 IP 192.168.1.6.80 > 10.0.0.1.47401: . ack 177 win 1716
Jetzt kann hier auch ein Verbindungsabbau gesehen werden, das können zwischen drei und vier Pakete sein:
Im obigen Fall erfolgen die Schritte 2 und 3 in einem Paket. Es ist aber auch möglich, eine Verbindung halboffen zu halten, dann kann nur noch eine Seite senden, die andere schickt dann nur noch ACK-Pakete.
Wird ein genauerer Blick auf die Antwort geworfen, so kann das hier gesehen werden:
HTTP/1.1 200 OK Vary: Accept-Encoding Content-Encoding: gzip Last-Modified: Thu, 30 Dec 2010 15:09:38 GMT ETag: "1886677020" Content-Type: text/html Accept-Ranges: bytes Content-Length: 4321 Connection: close Date: Thu, 01 Jan 1970 01:09:41 GMT Server: lighttpd/1.4.28
Danach folgt eine Leerzeile und Binärdaten. Der Server hat den Inhalt der Webseite mit gzip (Content-Encoding: gzip) gesendet. Wer sich an den Request erinnert, da stand unter anderem:
Accept-Encoding: gzip
Daher wurde hier alles gepackt verschickt. Dabei ginge es auch anders, das deutet der Server mit
Vary: Accept-Encoding
an, er könnte die Daten auch anders ausliefern, vermutlich ungepackt.
Aus diesem Grund hatte ich auch noch lug2.pcap erstellt, da sieht man dann die Daten vom Server in der Antwort ungepackt.
Wer sich über das Datum wundert: Der 1.1.1970 ist der Start der Unix-Zeit, er enstpricht 0 Sekunden. Von dieser Zeit an wird die Zeit in Sekunden gezählt. Der Webserver hier war aber mein DockStar, ein kleines embedded Linuxsystem. Scheinbar kann der sich die Uhrzeit nicht merken und fängt dadurch beim Einschalten bei 0, also beim 1.1.1970 an.
Zum Teil hatten wir es beim letzten Mal schon gesehen: Der Browser analysiert die erhaltenen Daten. Dabei gibt der Content-Type Auskunft darüber um was für Daten es sich handelt. Bei reinen HTML-Dateien steht da dann zum Beispiel:
Content-Type: text/html
Der Browser kann diese Daten direkt darstellen. Dazu analysiert er aber erst die Datei ob da noch weitere Elemente vorliegen, so wie verwendete CSS-Dateien, eingebettete Links, Bilder, etc.
Wenn alle Elemente vorliegen, fängt der Browser an zu rendern, das heißt er versucht die Elemente in der angegebenen Weise zu arrangieren, so dass sie darstellbar werden. Da hat dann beispielsweise die aktuelle Browsergröße einen Einfluss darauf, etc.
Hier wird auch oft die meiste Zeit beim Surfen gewartet: Oft hilft deswegen auch keine schnellere Leitung.
Was passiert, wenn es sich um nicht-HTML-Dateien handelt?
Dann schaut der Browser anhand des Content-Types nach, ob er ein Plugin zur Darstellung hat. Die URL (about:plugins im Firefox gibt hier Auskunft oder auch Edit -> Preferences -> Applications.)
Ist das nicht der Fall, so wird in den Dateien /etc/mailcap oder ~/.mailcap nachgesehen, ob hier steht, welches Programm die Daten anzeigen kann. Der Firefox fragt dann aber in aller Regel nach, ob er das Programm auch verwenden soll, ob eine Alternative dazu verwendet werden soll oder ob die Daten nur gespeichert werden sollen.
In der mailcap steht dann zum Beispiel:
application/pdf; /usr/bin/gv '%s' ...
Das heißt bei PDF-Dateien würde er hier das Programm gv starten um die Daten anzeigen zu lassen. Oft gibt es aber mehrere Varianten, zum Beispiel wären auch xpdf oder evince eine Möglichkeit. Normalerweise wird die erste genommen, manche Programme schlagen das auch vor, bieten aber die Option, ein anderes auszuwählen.
Das praktische Vorgehen ist meistens ein Abwarten der Fehlermeldung im Browser. Hat man eine, so ist der Rest schon fast selbsterklärend. Oft sind es DNS-Probleme, das heißt der Name konnte nicht aufgelöst werden oder gelegentlich gibt es auch Routing-Probleme: Der Zielserver ist über das definierte Routing nicht zu erreichen.
DNS kann am einfachsten mit dig getestet werden, z.B.:
dig www.lug-erding.de
Führt dies nicht zur IP-Adresse, so sollte man einmal versuchen den ganzen DNS-Baum durchzuhangeln. Das heißt man befragt die Root-Nameserver für den zuständigen de-Nameserver, den befragt man für den für lug-erding.de zuständigen Nameserver und diesen wiederum nach der IP-Adresse für den Namen www.lug-erding.de. Einzelne Nameserver können bei dig mit dem @-Zeichen angegeben werden, zum Beispiel:
dig www.lug-erding.de @ns9.nameserverservice.de
oder gleich mit der IP-Adresse:
dig www.lug-eding.de @85.25.128.54
Das durchhangeln kann dig mit der Option +trace selbständig machen:
dig +trace www.lug-erding.de
Wenn die IP-Adresse bekannt ist, kann zum Beispiel mit telnet getestet werden, ob der Server einen offenen Port hat und reagiert, also zum Beispiel:
telnet www.lug-erding.de 80
Gibt es die Meldung
telnet: Unable to connect to remote host: Connection refused
so ist der Webserver nicht am Laufen, er ist vermutlich gecrasht. Da kann man dann wenig machen, es sei denn, es ist der eigene Webserver...
Um festzustellen ob es sich um ein Routing-Problem handelt, bietet sich das Programm traceroute an. Per default sendet das Programm UDP-Pakete an das Zielsystem. Normalerweise sind es drei Pakete an die fortlaufenden Ports ab 33434.
Nun wie funktioniert das auffinden der Router zum Ziel? Ganz einfach, wir hatten schon das TTL-Feld im IP-Header. Jeder Router reduziert diesen Wert um eins bis das Paket am Ziel ist oder der Wert Null erreicht wird. Das soll verhindern, dass Pakete ewig im Kreis laufen.
Bei einem Wert von Null passieren in der Regel zwei Dinge:
Traceroute spielt mit dieser TTL. Beim ersten Paket das versendet wird, ist die TTL auf 1 gesetzt. D.h. der erste Router muss das Paket schon verwerfen und ein ICMP senden. Damit hat man schon den ersten hop. Danach wird die TTL nach und nach erhöht, bis man am Ziel angekommen ist oder wo auch immer die Pakete verloren gehen.
Das funktioniert recht gut, allerdings spielen nicht alle Router mit, nicht jeder generiert ein ICMP Time Exceeded Paket. Dann werden nur Sterne (*) statt der Router-IP-Adresse angezeigt.
Für den ersten Test des Routings, sollte man die Option -n verwenden, dadurch werden die IP-Adressen angezeigt und es wird nicht versucht den Namen per DNS zu ermitteln. Hat man einen problematischen Router gefunden, dann hilft der DNS-Name oft herauszufinden, wo er stehen mag. Eine whois-Abfrage kann auch den Provider liefern. Ob dieser dann aber überhaupt auf Beschwerden reagiert, ist eine andere Frage...
Das Programm traceroute kann statt UDP-Pakete auch ICMP-Pakete, wie sie ping verwendet, benutzen. Dazu ist die Option -I da. Die lokale Routingtabelle kann unter Unix einheitlich mit netstat -r ausgelesen werden. Beil Linux geht auch einfach das route-Kommando. Hilfreich ist auch hier oft die Option -n, sie schaltet wieder die Namensauflösung ab.
Den ARP-Cache kann man mit arp -a aufgelistet werden. Die Einträge werden aber in der Regel, sofern kein Datenverkehr mit der Adresse besteht, nach 15-45 Sekunden gelöscht, man muss schon schnell schauen. Auch hier kann die Option -n mit dem gleichen Effekt verwendet werden.
Wenn alle Stricke reißen, dann kann tcpdump eine gute Wahl sein. Da sind Fehler aber nur mit geübtem Auge zu erkennen und oft sieht man vor lauter Bäumen den Wald nicht. Während tcpdump in der Regel bei den unteren Protokollen sich gut auskennt, können die höheren Protokolle mit dem Programm wireshark gut analysiert werden. Dafür empfiehlt es sich jedoch, die Daten erst mit tcpdump in eine Datei zu schreiben und als normaler Benutzer diese in wireshark einzulesen.
Der Grund dafür ist einfach: wireshark ist sehr mächtig und analysiert sehr viele Protokolle. Da ist es eigentlich normal, dass dort noch viele Fehler enthalten sind, die vielleicht durch speziell konfigurierte Pakete ausgenutzt werden könnten. Da ist es dann nicht klug, diese live als Benutzer root analysieren zu lassen. Zeitversetztes Einlesen der Datei in wireshark als normaler Benutzer entschärft das dann deutlich.
Wir haben nun gesehen, was bei einem einzelnen Mausklick im Browser im Hintergrund alles passiert und welche Prozesse involviert sind. Wir sind sogar bis in die Paketebene hinuntergegangen und haben diverse Dinge beobachten können.
Gewöhnlich verschwendet man daran keinen Gedanken: Es funktioniert ja auch in der Regel recht gut. Warum sollte man sich also Gedanken darüber machen, was unter der Haube passiert? Die meisten werden es in gewöhnlich nicht, geschweige denn sich einmal im Detail ansehen, was da wirklich passiert.
Auf der anderen Seite gibt einem jedoch das Verständnis ein wenig Sicherheit im Umgang mit den Internet-Diensten. Diesen Punkt hatten wir allerdings noch nicht betrachtet, ich hatte es erst überlegt: Sicherheit! Da wir nun alle im Detail wissen, was abläuft, kann man sich auch relativ einfach überlegen, wo überall etwas schief gehen kann und vor allem, wenn das einer mit Absicht macht.
Ich glaube aber, das wäre dann doch zu viel für einen Abend gewesen, daher hatte ich den Punkt weggelassen. Vermutlich muss dafür das Wissen sich erst noch ein wenig festigen, bis man ein Auge dafür entwickelt, was man alles anstellen kann.
Wer aufgepasst hat, der weiß jetzt auch, wie sinnlos Websperren per DNS sein können: Sie treffen nur diejenigen, die sich nicht auskennen. Sonst nimmt man einfach einen anderen Nameserver, zum Beispiel den von Google: 8.8.8.8oder den von Quad9: 9.9.9.9. Auch one.one.one.one stellt einen öffentlich abfragbaren Nameserver parat: 1.1.1.1 Wie soll man deren Antworten nicht nur filtern, sondern auch noch verändern?
Oder soll mit den DNS-Sperren sämtlicher DNS-Verkehr geblockt werden, außer zum lokalen Provider? Das dürfte extrem schwer sein zu rechtfertigen. Wobei T-Home das durchaus macht(e): Da war zumindest damals eine Abfrage des Google-Nameservers blockiert.
Warum alles fast immer so einwandfrei läuft ist recht einfach: Das Internet ist in den mehr als 40 Jahren die es existiert darin gewachsen. Aber dennoch können immer wieder Probleme auftauchen, sie sind nur so selten, dass es einem meist nicht auffällt. Wenn mal eine Webseite nicht funktioniert, dann braucht man in der Regel nicht lange warten, bis das repariert wurde.
Und in vielen Fällen gibt es Redundanzen. So schreibt das DeNIC sogar vor, dass wenigstens zwei Nameserver für eine DE-Domain vorhanden sein müssen. Idealerweise sollten diese auch nicht auf dem gleichen Netzwerk sein, sie sollten nach Möglichkeit auch in unterschiedlichen Netzsegmenten liegen.
Man kann man mit DNS auch noch so einiges mehr anstellen, so wie es zum Beispiel Akamai tut: Sie beschleunigen darüber die Zugriffe auf Webserver. Ein Verfahren dabei ist, dass Akamai weltweit Webserver für ihre Kunden betreibt und den Traffic auf den nächstgelegenen Webserver umleitet.
Wie machen die das? Ein Verfahren ist nun leicht zu verstehen, nehmen wir zum Beispiel www.rtl2.de. Die Nameserveranfrage offenbart es:
www.rtl2.de. 3600 IN CNAME www.rtl2.de.edgesuite.net.
Das ist nicht ungewöhnlich, die Namensauflösung wird auf den rechten Namen weitergeleitet. Das ist ein Nameserver von Akamai. Dieser sieht nun, woher der Client kommt. Das dürfte nämlich von der IP-Adresse des ISPs kommen.
An Hand dieser Adresse kann Akamai nun feststellen, in welcher Region der Anfragende (vermutlich) sitzen wird. Um ihm dann den nächstgelegenen Server, möglichst der mit der geringsten Load, zuzuordnen, gibt es einen zweiten CNAME:
www.rtl2.de.edgesuite.net. 21600 IN CNAME a1195.g.akamai.net.
Für diese Namensauflösung muss nun ein Nameserver von Akamai befragt werden, der in der Nähe liegen sollte. Dieser weiß, welche Webserver die geringste Last haben und liefert dessen IP-Adresse aus. Damit diese schnell reagieren können, ist die TTL des Nameservereintrages recht kurz:
a1195.g.akamai.net. 20 IN A 95.100.249.122 a1195.g.akamai.net. 20 IN A 95.100.249.113
Das sind nur 20 Sekunden, nach dieser Zeit muss die Namensauflösung erneut angestoßen werden. Dann könnte zum Beispiel die Antwort so aussehen:
a1195.g.akamai.net. 20 IN A 77.67.20.18 a1195.g.akamai.net. 20 IN A 77.67.20.41
Und offenbar muss sich das bei der Performance rechnen: Die zusätzlichen Namensauflösungen scheinen durch den Standortvorteil gerechtfertigt zu sein, zumindest ist Akamai gut im Geschäft...
Ich denke, dieses Prinzip dürfte nun unter anderem nachvollziehbar sein, zumindest wenn Ihr mir bis hier folgen konntet...
Dirk Geschke, dirk@lug-erding.de
